
| ||
Mon 2025-06-16
Fri 2025-06-13
Thu 2025-06-12
Wed 2025-06-11
Tue 2025-06-10
Mon 2025-06-09
Sun 2025-06-08
Search
Archives
2024
12 11 10 09 08 07 06 05 04 03 02 01
2023
2022
2021
2020
2019
2018
2017
2016
2015
2014
2013
2012
2011
2010
2009
2008
2007
2006
2005
2004
2003
One good site
MDN
Nelson Minar
Blog licensed under a Creative Commons License
|
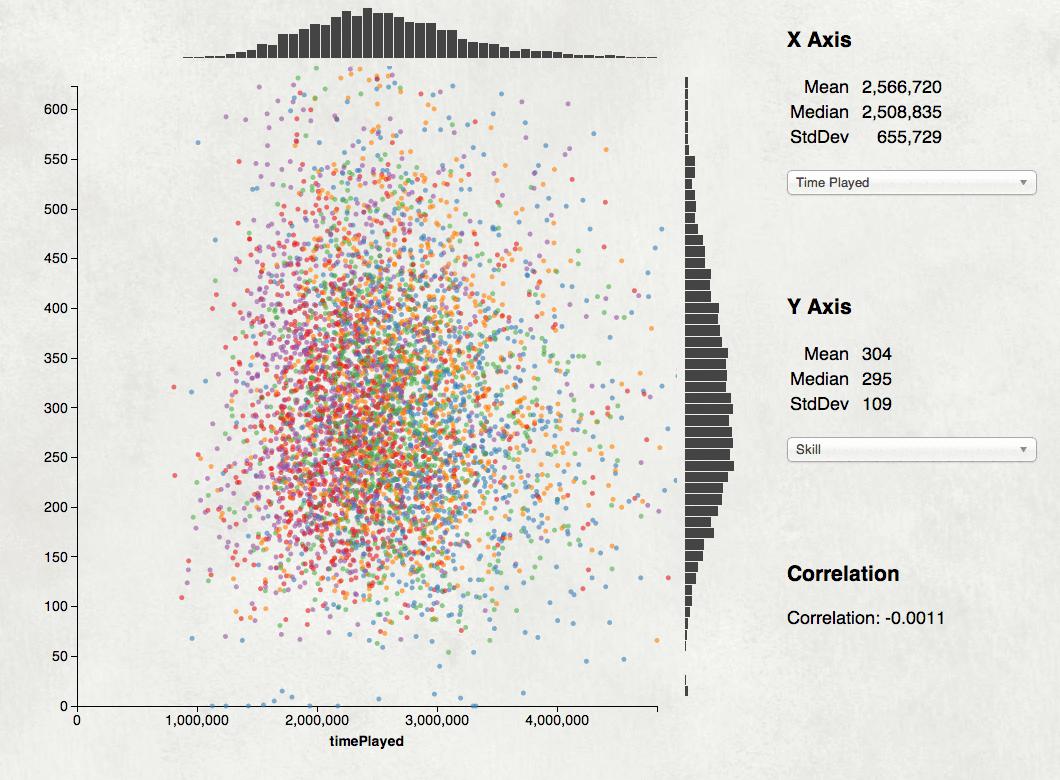
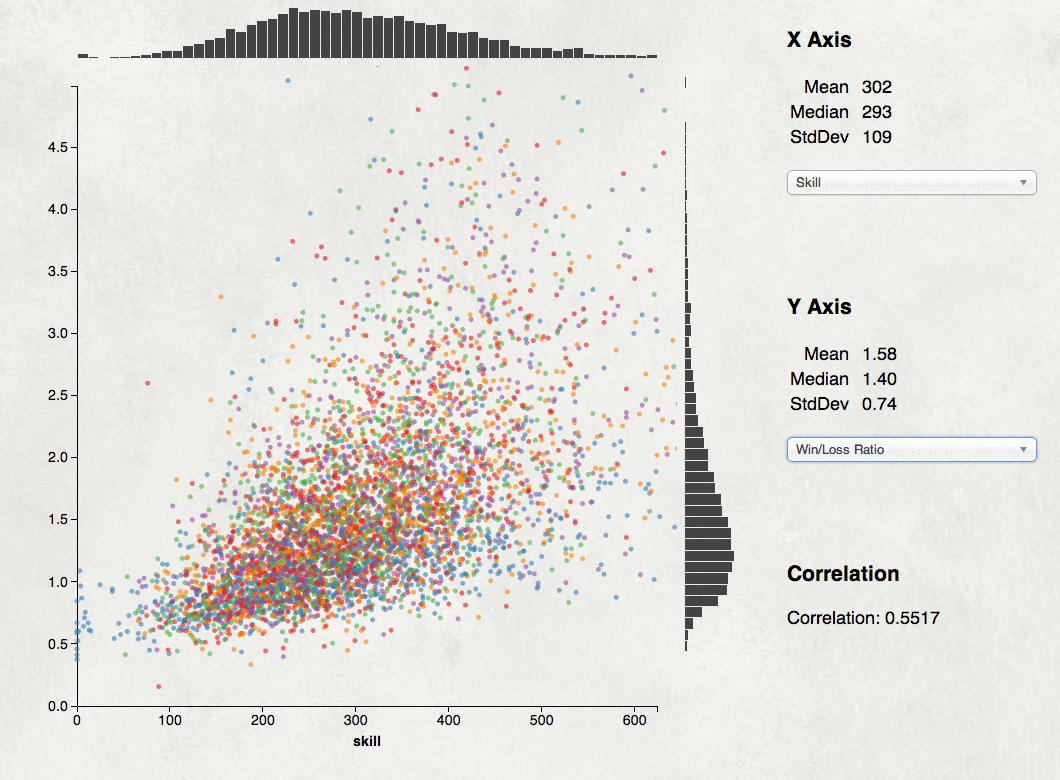
My tweet last night “Node.js is the MongoDB of programming languages” got enough response I feel I need to explain it a bit. It’s an awfully snarky thing to say, but it has some truth. MongoDB used to be the cool kids’ database. It’s appealing when you start using it: good docs, easy to get going, a plausible story on performance. NoSQL is exciting and MongoDB is an easy NoSQL system to try. But then people started looking closer and finding all the ways it broke and now MongoDB is out of favor, at least for serious production servers. Node.js is now the cool kids programming language. It’s appealing; good docs, clean slate of libraries and tools, fast VM, and a plausible attempt at server performance. Non-blocking systems are exciting and Javascript closures make continuation programming easy. But now people are looking closer and finding all the ways Node.js is awkward or brittle and one starts to wonder. I’m not saying Node.js is bad. There’s a lot of good in it, I particularly like that it’s made non-blocking programming more accessible than Python or Java or Nginx has. Mostly I’m just mocking the fashion of the month. It is a shame that people are rushing to this Brand New Thing without knowing the history and potential pitfalls. Just like we learned with MongoDB that ACID is hard, Node users are now discovering that reasoning about continuations is hard and memory management with closures is tricky, not to mention unwinding the stack on errors. The Node community is hard at work on improving things, hopefully that development process will lead somewhere productive. For a more hilarious view on MongoDB and Node.js see Mongo DB Is Web Scale and Node.js is Bad Ass Rock Star Tech. Just finished another game visualization project, graphs of stats for the top 5000 BF4 players. It makes scatterplots for the player population of statistics like skill score vs time played, win/loss ratio vs. skill, and kill/death vs. win/loss. Lots of details in this Reddit post. 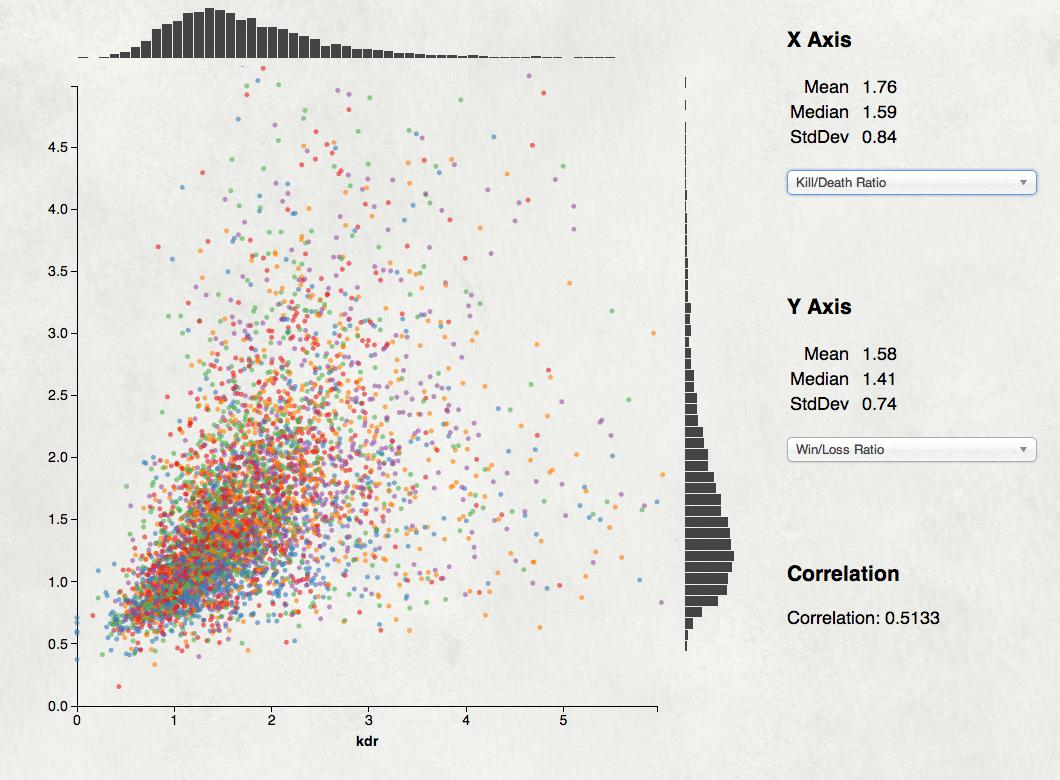 Another fun D3 project; scrape a bunch of data, cook it into a 2 megabyte CSV file, then do custom visualizations. I like the way the scatterplot came out and may re-mix it as a generic data exploration tool, a sort of GGobi lite in your web browser. Drop a CSV file into your browser window and get a simple tool for exploring it for correlations. It’s frustrating trying to get attention for projects like this. All I know to do is post it to the relevant subreddit and hope for the up-votes, but that’s pretty random. My Reddit attempt for the LoL lag tool failed, and a site I worked about 50 hours on has had a total of a few hundred visitors after a week. Discouraging. I had no idea Microsoft’s Bing Ads included an option to import from Google AdWords. Complete with simple OAuth-like authentication and seamless data import. It’s been able to do that for at least a couple of years, I only learned about it today when setting up a Bing campaign. 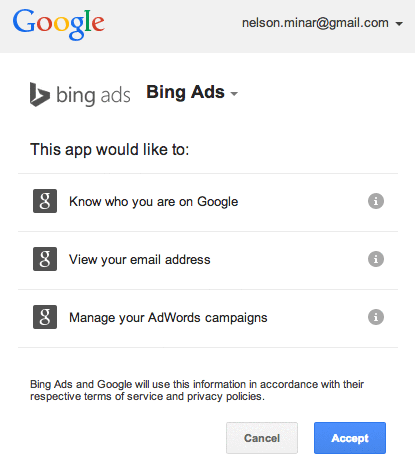 Warms my heart to think my AdWords API project helped enable some data portability for Google customers. That’s essential to having a competitive market. Google AdWords is nearly a monopoly, so much so I’m surprised there’s not more anti-trust interest in Google’s ad business. Allowing customers to bring their data to competitors is a valuable step in staying honest and legal. The drawback is Bing’s ads have to mirror Google’s crazily complex data model. (Quick, what’s an AdGroup, and how is it different from a Campaign or a Creative?) I also recently set up my first AdWords campaign in years and the frontend product is really complicated and confusing. It’s been nearly ten years since I worked on the AdWords advertiser UI, I was sad to see that it hadn’t gotten any simpler or clearer for advertisers. I just released Logs of Lag, a small project I’ve been working on. It’s a netlog analyzer for the game League of Legends. You drop a log file from the game on it and the tool gives you a nice report. Not a huge thing, but it’s been useful to me already. 
The webapp is another of my line of client-heavy programs. It all runs in static files, no server needed at all, the parsing and rendering is all done in the browser. I really like this style of programming, it’s fun and interactive and easy to scale. I did end up making a simple CGI server for storing log files so that people could share reports with friends. I may yet rewrite that to just use S3 as a filestore and bypass my server entirely. The code is on GitHub. There’s a new history of Perl making the rounds now that’s worth reading, if nothing else then for the dissonance of reading a whole thing written about Perl in the past tense. It reminded me of a bet my friend Marc and I made back in 1999 or so. Marc and Nelson will agree that Python has more mindshare than Perl on May 1, 2004. If so, Nelson gets the contents of this envelope. If not, Marc does. In 2004 I conceded he won the bet, based on this evidence of Google search result counts: Perl: 28M. Python: 14M I don't think anyone would argue that Perl is still more popular than Python in 2014. I looked at those measures again today, but given how goofy Google’s results count can be I don’t put too much stock in this: Perl: 28M. Python: 45M I wish I'd taken up his 2004 follow-on bet: Groovy vs Python. Oops. Meanwhile we both missed the language right under our noses, Javascript. Mostly I’m just grateful Java is on the way out. If it weren’t for all the work put into JVM efficiency I think it’d be entirely dead now. Interesting report of stolen Bitcoins, a phishing scam involving a Google ad. I just confirmed that the phishing ad is still running on Google on a search for blockchain. 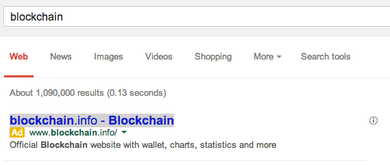 I don’t much care about the Bitcoin part of this, but Google should really not be selling ads with fake URLs on display. The indie game industry has been shifting in the past few years to a pre-funding model. Gamers pay for games before release, either via Kickstarter campaigns or by buying games in alpha release or Steam Early Access or the like. A lot of neat games have been funded this way (see: Minecraft) but I worry it’s bad for game consumers. We’re no longer being asked to buy a game, we’re buying something completely ephemeral, the idea of a game. We hope that maybe someday the game will be released and we can play it. And we get no guarantee of a quality finished project. (See Clang, which cynically claimed their unplayable alpha tech demo counted as a game release). Games are no longer really released, they are put out as an “alpha”, then a “beta”, then laughably a “gamma”. Really, why bother even finishing a game if people will pay you for your game anyway? Avoid the whole review cycle! The most predatory of these “buy the game that does not exist” things I’ve seen yet is Star Citizen. They have collected $44 million for a game where you fly around spaceships in a giant procedurally generated universe. Except that universe doesn’t exist and last I heard the only code you could actually run lets you look at a rendered spaceship sitting motionless in a hanger. Nevertheless, people are paying hundreds of dollars for special rare spaceships in the hopes one day they can fly them. The Star Citizen project is not a game, it’s a marketing campaign for a game. I sure hope it turns into a real game some day or a bunch of people are going to be disappointed. It’s many, many months behind schedule, to the extent there even is a schedule. Why bother shipping when you can just keep collecting money? adapted from a Metafilter
comment
There are two terrible web properties out there that everyone hates, Scribd and Quora. Please don’t use them. Instead of Scribd just host a PDF anywhere, or upload text to pastebin or make a nice blog on WordPress or Medium or something. And instead of Quora use Ask MetaFilter or StackExchange. Scribd’s business model is to host documents in formats that are unusable. For instance, here’s a copy of the Declaration of Independence. Or rather, the free preview; you have to download it to read the rest and a one-day guest pass costs $9. Here’s a copy of Elliot Rodger’s insane manifesto. It starts “This is the story of how I, Elliot Rodger, came to be.” Only I had to retype that phrase; if I copy-and-paste I get “]fjs js tfh stgry gl fgw J, Hccjgt Tgmahr, eknh tg dh” because Scribd uses some stupid DRM font. Easy enough for a pirate to reverse engineer but impossible for normal use. They also broke “Find”; there’s some Javascript thing overriding the browser that doesn’t seem to work. Quora’s business model is to trick people into sharing information for free, then put it behind a login. It’s like Experts Exchange 2.0! For instance, on Quora you can read Who owns the copyright on content contributed to Quora? Only you can’t just read the text. Depending on your history with the site and the way you got there you may see a giant popup demanding you log in obscuring the page, or the first answer clear and then the rest blurred, or if you're lucky just the page. It appears nondeterministic. Both businesses are deliberately trying to lock up text content to make it harder to access, to force users to pay or share advertising data or some such bullshit. The part that kills me is some engineer actually wrote code to deliberately break document sharing on the web. It’s terrible. Update: the Quora CEO responded on
Hacker News to correct me that Quora neither runs ads nor
charges users. At the moment, they apparently have
no revenue.
|
|

{kind=link}
{kind=link}